This is a global announcement. This is a global announcement. This is a global announcement. This is a global announcement. This is a global announcement.
Learn More >>
In the blog post below, I am going to provide background information about the Googlebot CSS and JS notification, .and the robots.txt file, and then explain the status (as of 7/28/15) of the robots.txt update.
Google learns about content on the Internet via a program called “Googlebot”. Googlebot looks at websites and webpages to examine what content is present, new, and/or updated, etc., in a process known as “crawling”. By crawling (exploring/learning about) web pages, Google is able to “know” what web pages are out there on the Internet, and in turn, can show the best pages when a user performs a Google search.
The location of the robots.txt file in your website root directory.
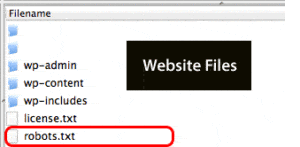
Robots.txt is the name of a file that is present alongside all of the other files that comprise your website. Whereas .jpg files are images, and .PDF files are PDF documents, robots.txt has a special job.
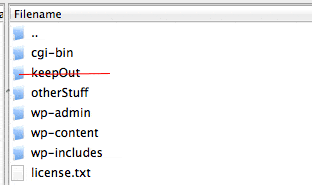
robots.txt tells Googlebot what website files it can and cannot access ("see")
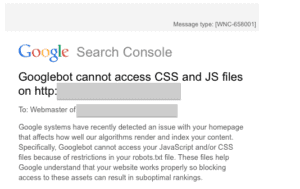
The recent Googlebot notification that many dentists physicians received.
From a technical standpoint, the fix is to add directives in the robots.txt file to allow Googlebot access to .CSS and .JS files. But as of this writing (7/28/15) there is no consensus as to the best way to balance access to these files and security concerns. As soon as more information becomes available I will post it here and on the SHD social sites.
Dr. Wank has been at the helm of Short Hills Design since he founded the company over a decade ago and is the author of the Small Business Web Design Workbook. Dr. Wank currently serves on the editorial advisory board for DentalTown magazine and writes their web development CE course.